09. April 2022
Dbt_start
Starting up with DBT
I just finished a course on DBT, provided by co:rise. They have a very interesting approach on online education. It isn’t just finishing a coupl of tasks in an online mask, but focuses on creating a learning community, guided by a couple of TA’s and in case of DBT curated by Emily Hawkin (Twitter). We had many project sessions to get into the topic, coding parties to get our weekly work done und such great fireside chats with Taylor Murphy or Emilie Schario
What is DBT
I don’t want to get too much into the modern data stack and the difference between ETL vs ELT, which is a topic surrounding DBT. Basically, I summarise what I learned about DBT and do a little bit of documentation of my work. Using DBT moves the heavy lifting of transforming data in the realm of the data warehouse. As storage gets cheaper, we can save untouched raw data from any source. Before going in the analysis process a capable Analytics Engineer prepares the data to be served in digestably modeled data pieces. Transformation and final storage both happen in the data warehouse. DBT makes it magically easy to do so.
What is DBT doing?
DBT-Core is built in python but doesn’t require any python knowledge to use. It comes as a CLI tool that connects to your data warehouse and transforms data based on .sql files. First of all, it provides a directory structure for each project to have a standardized workflow to handle your files. Secondly, it executes all queries according to the models inside you project structure, which also enables referencing models inside a query. AS the whole code base happens in a structured text format it is possible to document, version control the complete transformation phase. As well built as it is, dbt core also serves a comprehensive web based documentation for my project.
But when should I use DBT?
I think DBT can be used every time you do transformation in a database and want to serve the transformed data to a third party, let it be an analyst, an api or another model. It isn’t difficult to set up and once you learned the fundamentals, it makes working with sql much easier and more stringent, reproducible and documented.
Install & Connection
Using Adapter
Installing with homebrew brew install dbt-postgres
Multiple Adapters can simply be installed in parallel. Either by using homebrew or pip or as Docker image, if wanted. Each adapter is also available on github and can be installed from source.
There three kinds of adapter, which differ by support.
- supported by DBT like Postgres or Snowflake
- supported by Vendors such as Databricks and Teradata
- supported by Community for big enterprise databases, e.g. Azure or Oracle
In order to connect to a data source, the database and its credentials need to be configured in a profiles.yml file outside of the project directory. The specifics are dependent on the chosen adapter. Following, you see an example for connecting to a postgres Database.
profiles.yml Set Up
dbt init <procject>~/.dbt/profiles.yml
|
|
Handling multiple Environments
I need to have two different environments. One locally to test and develop dev and one that maybe sits in the cloud and is awaiting work prod. I found the official documentation on multiple environments a little bit confusing. The profile page describes how to set up the profile.yml and hints to add a new target, but I didn’t get what the correct syntax is and how to consider it, when running dbt. The run doc also mentions to add a new target, but has no syntax examples and it doesn’t get clearer for me in the adapter specific profiles page
Looking around stack overflow I decided to try some configuration, that look promising. My current profiles.yml with two environments now looks like this.
|
|
Running against a specific target can be considered with a --target flag.
To check the connection we can run dbt debug --target prod
Using DBT
Using DBT is all about transforming and modelling data. So lets get to it.
Modelling
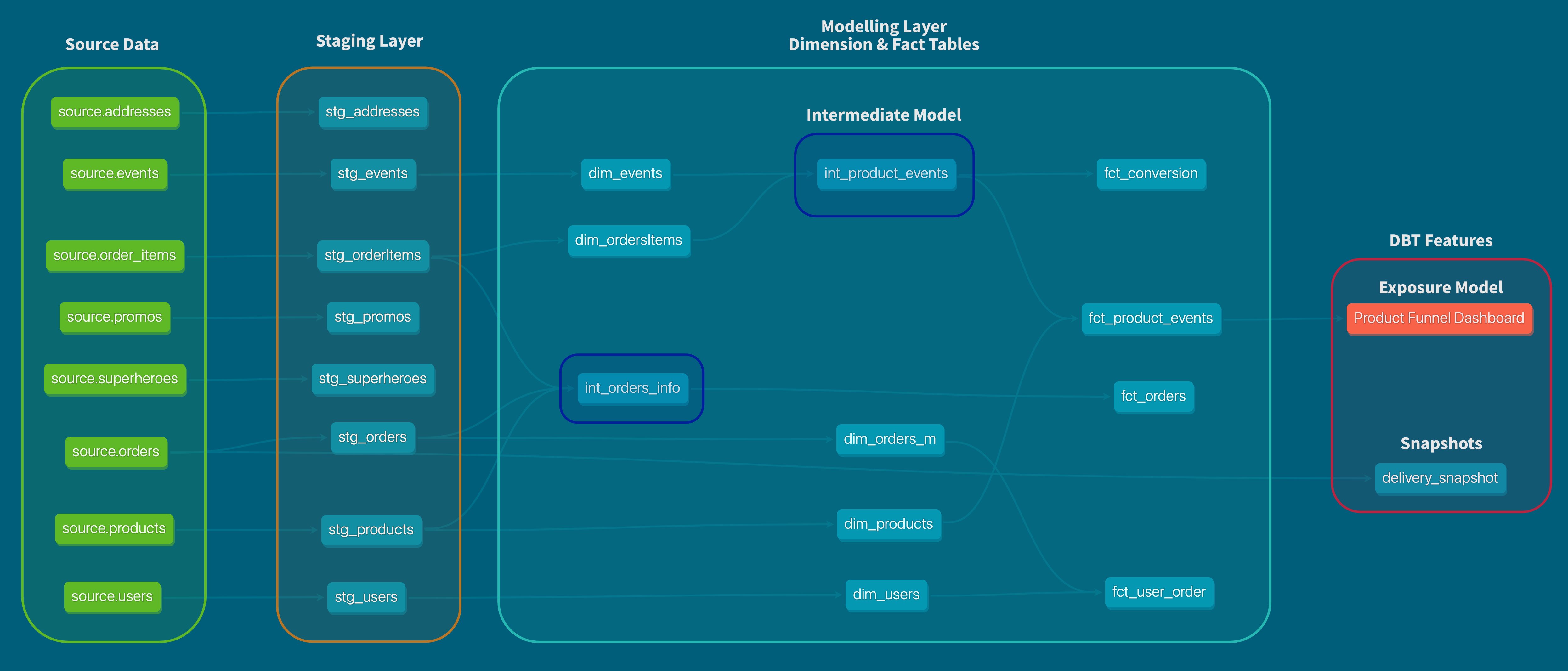
Modelling in this case describes transformation step between accessing source data and providing slick datasets specialised for a very specific use case. Hereby we can consider different modelling layers in between.
Source Data:
- untransformed source data, usually originating from an app, API or Logging/Tracking System
- No Transformation happened
Base/Staging Layer:
- It is considered good practice to stage all required data, without applying any heavy transformation.
- Only transformations may be some validity checks or NA Replacements.
Intermediate Model:
- Intermediate models make sense for very common data transformation, that are necessary in multiple different final models.
- These models are also good to improve readability and avoid very large complex single queries.
Dimension & Fact Tables:
- Dimension and Fact Tables are final datasets that can later be exposed to the public.
- Dimension can thereby considered as adjectives. The describe the facts more detailed.
- Fact on the other hand are more like verbs and stand for specific events, that are happening.
Exposure Models:
- In DBT it is possible to create specific exposures for data models, that are ready to face the outer world.
- These are no direct models, but only serve documentation purposes for the DBT inherent documentation.
More Information about how to build your models and your DAG in this coalesce talk from 2020. Below you can see the DAG I generated during my course at corise. I marked the individual modelling layers.
Accessing the source
Sources are defined in source.yml inside the models folder. Here we can define our database, schema, tables to state the least minimum that is needed to work properly. Much more is configurable, as meta information or tests on specific columns. For the Spotify example above, my source looks like below. Hereby I want to account for the different database names I call, depending on the different environment.
|
|
Each source can be accessed, by referencing to it in a sql model FROM {{source('source', 'album')}}
Staging
it is considered best practice to stage all tables used for modelling without expensive transformation. Only minor changes from the source should be applied here, like handling NAs or Zeros, taking care of units or column names.
stg_album.sql:
|
|
Right now I haven’t done any further modelling for my Spotify project. I’m gonna write an Update, when I progressed a little bit further.
My example project created during a corise course can be found on my gitlab Account. The Repository shows a small but complete project and provides an overview of different functionality. An even better source to get a feel of a real dbt use case is the Gitlab DBT Guide.